Ich baue Software vom Systemdesign bis zum Deployment. C++, C#, x86-Assembler, Computer Vision. Mitgründer von FuseGrid.
Ich bin Luca, 24 Jahre alt, und denke Softwareentwicklung ganzheitlich, vom übergeordneten Systemdesign über die Implementierung bis ins fertige Produkt. Meine Tiefe liegt in C++, C# und x86-Assembler, mit dem ich seit rund zwei Jahrzehnten arbeite. Das ist kein Selbstzweck; es bedeutet vor allem, dass ich Probleme auf Instruktionsebene lesen kann, wenn ein Profiler mit den Schultern zuckt.
Mein Weg in die Software führte über die Werkstatt. Ich bin gelernter Elektriker (Geselle) und gelernter Anwendungsentwickler. Beide Ausbildungen haben mich geprägt: die eine hat mir den Blick für reale Umgebungen gegeben, die andere das Handwerk für saubere Systeme.
Aktuell arbeite ich an FuseGrid, einer Plattform für KI-gestützte Baustellenplanung, Dokumentation und Verwaltung. Das Projekt wurde im September 2025 vom Land Niedersachsen mit dem Gründungsstipendium der NBank gefördert. Formell gegründet ist das Unternehmen noch nicht, die Architektur steht aber und das Vision-Modell trainiert auf echten Bauplänen. Mein Anspruch an FuseGrid ist derselbe wie an den Rest meiner Arbeit: Software, die funktioniert, weil sie funktionieren muss.
Abseits der Arbeit fasziniert mich die Astrophotographie, besonders Deep-Sky-Objekte: Nebel, Galaxien und Sternhaufen, mit langen Belichtungen aus dem eigenen Garten heraus.
Ich antworte in der Regel am selben Tag. Am schnellsten geht es per E-Mail.
kontakt@lucawichmann.deEiner der interessantesten Bereiche meiner Arbeit ist Software, die bewusst versucht, nicht mehr wie Software auszusehen. Genau dort setzt Pawlisher an: ein Reverse-Engineering- und Recovery-Tooling für nativen, virtualisierten Code.
Der konkrete Gegner in diesem Fall ist Code Virtualizer von Oreans. Wer das Produkt nur oberflächlich kennt, denkt vielleicht erst an klassische Obfuskation: etwas Junk-Code, ein paar Sprünge, vielleicht verschobene Kontrollflüsse. Virtualisierung ist eine andere Liga. Der ursprüngliche x86-Code wird nicht bloß verschleiert, sondern in ein proprietäres Bytecode-Format überführt, das von einer eingebetteten virtuellen Maschine interpretiert wird.
Für einen Analysten bedeutet das: Der eigentliche Algorithmus ist nicht mehr direkt im Binärcode sichtbar. Sichtbar ist stattdessen ein Dispatcher, ein Satz von Handlern, ein VM-Kontext, virtuelle Operanden und eine Menge bewusst störender Struktur. Man debuggt nicht mehr einfach ein Programm. Man debuggt zunächst die CPU, die das Programm erfunden hat.
Der Schutz ist nicht nur deshalb wirksam, weil er groß und unübersichtlich ist, sondern weil er die Regeln verändert.
Bei einem klassischen Reverse-Me oder einer stark optimierten Release-Binary kann man immer noch erwarten, dass man es mit normalem Assembler, normalem Kontrollfluss und halbwegs vertrauten Werkzeugen zu tun hat. Bei einer virtualisierten Routine gilt das nicht mehr. Der semantische Inhalt einer Funktion liegt dann oft hinter mehreren Schichten:
Was Code Virtualizer zusätzlich unangenehm macht, ist Polymorphie. Die Struktur bleibt wiedererkennbar, aber die konkrete Ausprägung verschiebt sich von Build zu Build. Handler-Adressen ändern sich, Tabellen werden relativ statt absolut gehalten, Dispatch-Muster variieren, Bytecode-Layouts sind nicht stabil, und um die eigentliche Kernlogik liegt regelmäßig Material, das nur für Verwirrung existiert.
Das Ergebnis ist nicht “unvorhersehbar”, es ist aber instabil genug, dass statische Einmal-Analysen und schnelle Pattern-Matches in echten Targets schnell an ihre Grenzen kommen.
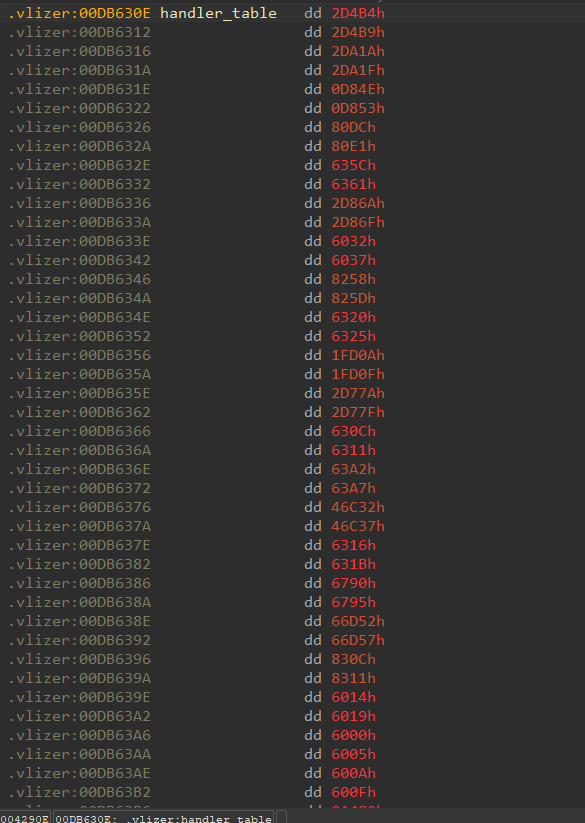
Ein kleines, aber typisches Detail ist die Handler-Tabelle selbst. Zum Beispiel liegen dort in der TINY32-Variante nicht direkt absolute Handler-Adressen, sondern relative Offsets, die erst zur Laufzeit gegen die Image Base aufgelöst werden.
Schon an so einer Stelle sieht man das Grundmuster: Die Struktur ist vorhanden und analysierbar, aber sie ist absichtlich gerade unbequem genug gebaut, dass ein schneller statischer Blick nicht mehr reicht.
Pawlisher ist mein Versuch, dieses Problem nicht mit einzelnen Ad-hoc-Skripten zu beantworten, sondern mit einer sauberen Pipeline.
Technisch ist das Projekt ein C++20-Werkzeug für Windows, mit einer nativen Analyse- und Recovery-Pipeline und einer eigenen Oberfläche auf Basis von ImGui und ImNodes. Auf der Analyse-Seite verwende ich unter anderem:
Der Punkt ist nicht, “einen Handler schön darzustellen”. Der Punkt ist, von einer unübersichtlichen, virtualisierten Native-Binary wieder zu einer Struktur zu kommen, auf der man argumentieren kann.
In groben Zügen sieht die Pipeline so aus:
Ein stark vereinfachtes Dispatcher-Muster sieht oft ungefähr so aus:
// stark vereinfacht und bewusst unvollständig
m_Ctx->next_handler = m_Ctx->handler_table[bytecode[m_Ctx->vip + opcode_offset]];
m_Ctx->vip += bytecode[m_Ctx->vip + advance_offset];
return ((void)(m_Ctx->next_handler))();Der Code ist kurz, aber die eigentliche Schwierigkeit sitzt im Detail:
vip im Kontext?Die Außenansicht auf Virtualisierung ist oft: “Man findet die Handler-Tabelle, dann liest man die Opcodes, dann ist das Thema erledigt”. In der Praxis ist das aber zu naiv.
Der erste harte Teil ist bereits die Bootstrap-Phase. Selbst wenn man einen VM-Entry gefunden hat, ist damit noch nicht geklärt:
Gerade bei Code Virtualizer ist diese Anfangsphase wichtig, weil dort viel absichtlich unruhig aussieht: relative Offsets, Trampoline, Dispatcher-Varianten, Initialisierungslogik, irrelevantes Rauschen. Der Schutz lebt davon, dass ein Mensch sehr schnell den Faden verliert.
An Varianten wie TINY32 oder FALCON32 sieht man gut, wie wiederkehrende Ideen unter wechselnder Oberfläche auftreten. Man findet denselben Grundgedanken des Dispatchers wieder, aber eben nicht in einer Form, die man einfach auf eine Signatur reduzieren sollte.
Deshalb arbeitet Pawlisher nicht rein statisch. Die interessante Ebene entsteht erst, wenn statische Analyse, gezielte Emulation und Semantik-Recovery zusammenkommen.
Damit das nicht abstrakt bleibt, hier zwei Ausschnitte aus der Form, in der Pawlisher intern über eine VM-Ausführung nachdenkt.
Zuerst die Idee eines einzelnen analysierten Ausführungsschritts. Für einen Schritt interessiert uns nicht nur der aktuelle Handler, sondern auch VIP vorher/nachher, beobachtete Semantik, potenzielle Replay-Fehler und ein möglicher Nachfolger-Snapshot:
struct InvocationStepResult
{
VmInvocationSnapshot input;
NativeInstructionSlice nativeSlice;
MicroexecutionOutcome microexecution;
SemanticState semanticState;
std::optional<VmAddress> vipBefore;
std::optional<VmAddress> vipAfter;
std::optional<VmInvocationSnapshot> successorSnapshot;
std::optional<VmAddress> successorHandlerAddress;
InvocationTerminalKind terminalKind;
VmAnalysisStatus status;
};Der wichtige Punkt daran ist: Pawlisher betrachtet einen Handler nicht isoliert, sondern als Zustandsübergang innerhalb einer virtuellen Maschine.
Darauf baut die nächste Ebene auf. Wenn genug dieser Schritte verstanden sind, kann Pawlisher daraus eine virtuelle Funktion und ihren Kontrollfluss konstruieren:
class VirtualCfgBuilder
{
public:
VirtualFunction RecoverVirtualFunction(const VmInstanceModel& model) const;
VirtualFunction RecoverVirtualFunction(
const VmInstanceModel& model,
const VmSetupSnapshot& snapshot) const;
VirtualControlFlowGraph BuildVirtualCfg(
const VmInstanceModel& model,
const VmInvocationSnapshot& entry) const;
};Der Kern von Pawlisher ist nicht “Disassembly hübscher machen”, sondern Bedeutung zurückgewinnen.
Ein einzelner VM-Handler ist zunächst nur nativer Code. Erst durch Kontext wird daraus eine Aussage wie:
Diese semantische Ebene ist entscheidend, weil sie die Brücke vom nativen Schutzcode zur virtuellen Programmlogik bildet.
In Pawlisher passiert das bewusst mehrstufig:
Dieses IR ist der eigentliche Wendepunkt. Ab da arbeitet man nicht mehr nur mit Handlern, sondern mit einer Zwischenrepräsentation, auf der sich Kontrollfluss, Zustandsänderungen und Datenabhängigkeiten deutlich sauberer diskutieren lassen.
Ich halte diesen Schritt für zentral, weil Devirtualisierung ohne gute Zwischenrepräsentation schnell in einer Sackgasse endet: Man sieht immer mehr Details, aber gewinnt immer weniger Verständnis.
Ein Beispiel für die Art von semantischer Verdichtung, die mich interessiert, ist etwa:
native handler slice
-> liest Bytecode-Operand
-> lädt oder schreibt virtuellen Zustand
-> beeinflusst Flags oder Ziel-VIP
-> dispatcht zum nächsten Handler
semantic effect
-> "schreibe Konstante in VM-Register"
-> "addiere Operand auf virtuellen Akkumulator"
-> "verzweige abhängig von ZF"Genau dort wird aus Schutzmechanik wieder Programmlogik.
Bei solchen Themen ist die Grenze zwischen interessanter technischer Einordnung und unnötiger Offenlegung schmal. Ich finde es sinnvoll, sie bewusst zu ziehen.
Ich beschreibe gern:
Ich beschreibe bewusst nicht im Detail:
Software-Schutz lebt auch davon, dass nicht jede Recovery-Strategie sofort vollständig öffentlich seziert wird. Ich teile gern Architektur, Denkweise und Problemform. Den Rest darf ruhig noch etwas verborgen bleiben.
Code Virtualizer ist interessant, weil es Software nicht einfach nur versteckt, sondern in eine andere Ausführungswelt verschiebt. Pawlisher ist mein Werkzeug, um aus dieser anderen Ausführungswelt wieder Struktur zu gewinnen.
Solche Probleme sind selten elegant im klassischen Sinn. Sie sind widerspenstig, asymmetrisch und oft absichtlich feindselig gegenüber Analyse. Gerade deshalb lohnt sich sauberes Werkzeug, präzises Denken und die Bereitschaft, sich durch komplexe Details zu arbeiten, bis wieder Form erkennbar wird.
Dieser Text ist deshalb eher ein erster Aufriss als ein vollständiger Rundgang. Über einzelne Teile, etwa Handler-Semantik, Virtual CFG Recovery oder die Rolle von IR in solchen Pipelines, wird es später vermutlich noch einen zweiten, deutlich fokussierteren Beitrag geben.
Der aktuelle KI-Markt ist voller Software, in die “irgendwie auch noch KI” eingebaut wurde, ohne dass wirklich klar ist, welches Problem damit eigentlich gelöst werden soll. In vielen Fällen endet das dann bei einem angebundenen LLM, einem Chatfenster in der Ecke und einer Präsentation über Innovation. Die laufenden Kosten sind hoch, der praktische Nutzen bleibt oft überschaubar, und bei Themen wie DSGVO, Datenfluss und Produktverantwortung wird es schnell unangenehm.
Mich interessiert an Machine Learning eine andere Frage: Gibt es ein reales Problem, das ohne spezialisierte Modelle, saubere Datenwege und eine durchdachte Pipeline schlicht nicht robust lösbar ist? Bei FuseGrid ist die Antwort aus meiner Sicht klar ja.
Denn Baupläne sind keine sauberen, standardisierten Maschinen-Eingaben. Ein Grundriss ist entweder Scan, PDF-Export, Screenshot, Exposé-Auszug, Vektor-Ableitung oder ein schlecht komprimiertes Bild. Linienbreiten schwanken, Maßstäbe schwanken, Symbole sind nicht einheitlich, Beschriftungen sitzen im Weg, und dieselbe semantische Struktur kann visuell sehr unterschiedlich erscheinen.
Genau dort beginnt die eigentliche Arbeit. Die ML-Seite von FuseGrid ist nicht einfach ein einzelnes Modell, das “ein bisschen Segmentierung” macht. Entscheidend ist, dass das Modell von uns selbst trainiert wurde, nur für unseren eigenen Anwendungsfall gebaut ist und genau auf diese Art von Grundrissen optimiert wurde.
Das Ziel ist nicht bloß, Pixel einzufärben. Das Ziel ist, aus Grundrissen wieder baulich verwertbare Struktur zu gewinnen.
Die aktuelle Segmentierungsseite der Pipeline arbeitet mit fünf semantischen Klassen:
0 background
1 wall
2 door_opening
3 window
4 door_geometryDiese Aufteilung ist bewusst gewählt. Für uns ist nicht nur interessant, dass irgendwo eine Tür vorkommt, sondern auch, wie sich Öffnung und Geometrie voneinander trennen lassen. Erst solche Unterschiede machen spätere Verarbeitungsschritte sinnvoll.
Nach meinem Kenntnisstand gibt es in dieser Form kein anderes System, das Grundrisse genau auf dieser Ebene segmentiert und dabei die für uns relevanten Bauobjekte so auftrennt, wie wir es tun. Gerade deshalb ist der interessante Teil nicht nur das Modell selbst, sondern die gesamte Umgebung, die darum gebaut wurde.
In vielen Bereichen kann man ein gutes Modell auf einen vorhandenen Datensatz werfen und danach über Feintuning sprechen. Bei Grundrissen funktioniert das nur sehr begrenzt.
Die Eingaben sind zu heterogen. Ein allgemeines Modell, das für alles ein bisschen zuständig ist, wird dabei schnell mittelmäßig. Für uns war deshalb früh klar, dass wir kein generisches System wollen, sondern ein Modell, das speziell auf unseren Anwendungsfall trainiert und abgestimmt ist.
Wir arbeiten mit einem privat kuratierten Datensatz, der die Grundrisse deutscher Baustellen sehr gut abdeckt. Genau diese Spezialisierung ist ein großer Teil der Qualität. Das Modell ist nicht dafür gedacht, alles Mögliche irgendwie zu erkennen. Es ist dafür gedacht, genau das, was wir brauchen, sehr präzise und zuverlässig zu segmentieren.
Im Kern geht es um hochwertige Segmentierung auf genau den Klassen, die für uns später baulich und technisch relevant sind. Das Modell muss nicht nur grob Vordergrund von Hintergrund trennen, sondern mit ausreichend Stabilität zwischen Wand, Fenster, Türöffnung und Türgeometrie unterscheiden.
Das Entscheidende ist dabei weniger ein Name für eine Architektur als die Tatsache, dass das gesamte Training auf diesen einen Use Case hin geschärft wurde. Dadurch entsteht etwas, das in der Breite bewusst enger ist, in der Tiefe aber deutlich stärker.
Zur Laufzeit ist vor allem wichtig:
Ein stark vereinfachter Blick auf die Inferenzseite sieht etwa so aus:
floor plan
-> preprocess / normalize
-> sliding windows
-> model inference per tile
-> weighted merge
-> class probabilities
-> structural postprocessing
-> masks + overlay + downstream shapesGerade bei Grundrissen ist dieses tiled Setup wichtig. Die relevanten Strukturen sind oft dünn, langgezogen und kontextabhängig. Man braucht also genug lokale Auflösung, ohne die gesamte Laufzeitseite unbrauchbar schwer zu machen.
Ein weiterer wichtiger Punkt ist, dass das Modell nicht auf einen Cloud-Service angewiesen ist. Es läuft lokal auf den Maschinen unserer Kunden und zwar auf der CPU. Das ist aus Produktsicht enorm wichtig, weil es Kosten kontrollierbar hält, Latenz vermeidet und die operative Hürde im Einsatz deutlich senkt.
Ein Punkt, den ich bei solchen Systemen wichtig finde: Gute Segmentierung endet nicht bei “wo ist Vordergrund?”.
In der Pipeline gibt es mehrere Mechanismen, die genau in diese Richtung gehen:
Bei Grundrissen reicht es nicht, irgendwo grob eine Fläche zu erkennen. Wände, Öffnungen und Türgeometrie sind topologisch und funktional relevant. Wenn man später aus dem Ergebnis mehr machen will als eine hübsche Heatmap, muss das Lernziel diese Struktur bereits widerspiegeln.
Ein weiterer Teil ist die Verdichtung des Trainingswissens in ein Einsatzmodell, das klein und schnell genug für die Praxis bleibt. Hohe Qualität allein reicht nicht, wenn ein Modell später zu schwer, zu teuer oder zu unhandlich für echte Kundenumgebungen ist.
Hier spielt Distillation eine Rolle. Vereinfacht gesagt geht es darum, Wissen aus stärkeren oder spezialisierteren Trainingskonstellationen so zu übertragen, dass am Ende ein kompakteres Modell entsteht, das trotzdem sehr viel von dieser Qualität mitnimmt.
Das ist konzeptionell spannend, weil es zwei Ziele zusammenbringt, die sich oft beißen:
Das Modell ist nicht nur gut in der Segmentierung, sondern zugleich performant genug, um lokal auf Kundensystemen zu laufen.
Zur Qualitätsseite gehört auch unser interner “Annotator”. Statt generischer Labeling-Software nutzen wir ein eigenes Werkzeug, das genau auf architektonische Grundrisse und unsere Klassen zugeschnitten ist. Das hilft dabei, die Datenqualität hoch zu halten und Korrekturen konsistent in denselben fachlichen Rahmen zurückzuführen, in dem das Modell später arbeiten soll.
Was mich an diesem Thema reizt, ist weniger das Schlagwort “KI” als die Präzision, die das Problem verlangt. Ein Modell für Grundrisse ist nur dann wirklich interessant, wenn es nicht bloß beeindruckend aussieht, sondern in echten Abläufen verlässlich funktioniert.
Genau deshalb ist für mich die eigentliche Stärke hier nicht irgendein allgemeines KI-Versprechen, sondern die Passform der Lösung. Das Modell ist auf einen eng definierten Zweck trainiert, liefert auf genau den relevanten Klassen hohe Qualität und bleibt gleichzeitig leicht genug, um lokal auf Kundensystemen auf der CPU zu laufen. Diese Kombination ist am Ende deutlich wertvoller als ein breiter, aber diffuser “AI inside”-Ansatz.
Vor allem aber reduziert sie den realen Arbeitsaufwand auf Kundenseite erheblich. Pläne müssen nicht mehr in demselben Maß händisch digitalisiert, nachgezeichnet oder manuell in eine weiterverarbeitbare Struktur überführt werden. Die ML-Modelle von FuseGrid assistieren genau an dieser Stelle, sparen Arbeitszeit, senken Kosten und nehmen einen Teil der repetitiven Arbeit aus Prozessen heraus, die bisher unnötig viel Handarbeit verlangt haben.
Gerade deshalb halte ich den Ansatz auch für außergewöhnlich. Nach meinem Kenntnisstand gibt es am Markt kein anderes System, das diese Art von Grundriss-Segmentierung in dieser Spezialisierung, Qualität und lokalen Einsetzbarkeit anbietet.